虎课网-专注职业教育
拖动LOGO到书签栏,立即收藏虎课网

数据挖掘之客户分群实战之k均值算法发布时间:暂无
1.【K-Means类聚】以样本间的距离为基础,将所有的观测划分到K个群体,使得群体和群体之间的距离尽量大,同时群体内部的观测之间的“距离和”最小。其中【K】代表总共要分的类即【K】个群组。【Means】代表在分析方法中要反复计算群体的中心即均值中心。

2.【K-Means类聚】使用的样本间距离定义为【欧式距离】。【误差平方】与【函数的计算公式】如图所示。

3.其意义在于当把一个整体分为K个群组之后,计算每个群组中所有点到该群组中心点的距离,把这些距离分别平方后加总得到该群体的误差平方和。将K个群体的误差平方和相加后的到总体误差平方和。

4.右侧所示图为【收入】与【年龄】的二维分布图。其误差平方和的计算方法为分别计算三个组的组内误差平方和再全部相加,实则为一个目标方法。【K均值】的目标为找到目标分组方法使目标函数最小。

5.【K-Means类聚】方法的流程如图所示。【K均值】在进行分析之前必须确定K的值。当完成第五步后要打散分组,回到第三步,重新计算每个个体到新的中心点的距离,用同样的方法将其分到距离最近的中心点所对应的群组中,并重复步骤至结果不会变化。

6.在屏幕中加入三个点使之作为中心点,对于原来的每个小蓝点个体分别计算它们到中心点的距离,选取距离最近的中心点并把个体分类至该群组中。
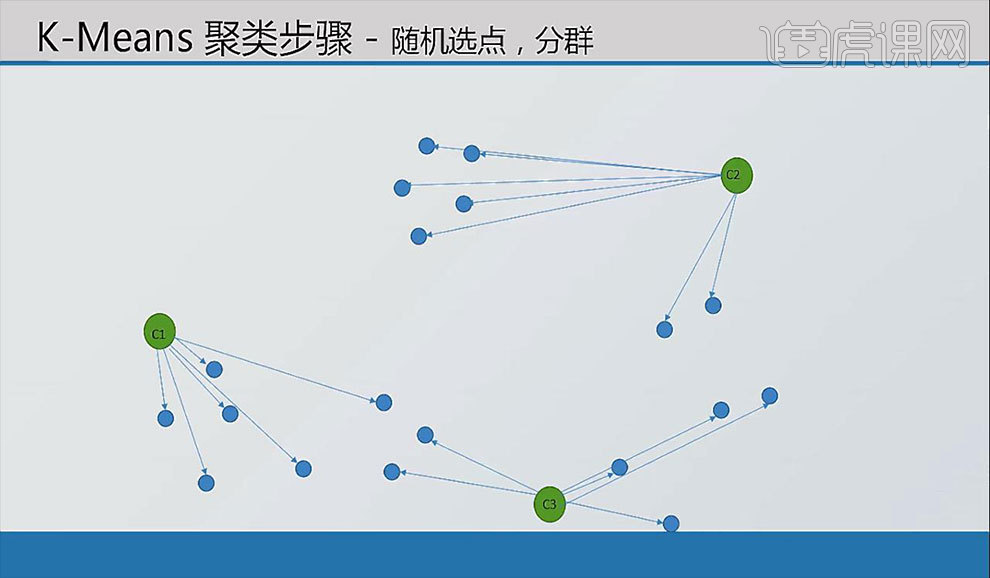
7.分组完成后用【计算均值】方法分别计算三个组的中心,得到新的中心点。
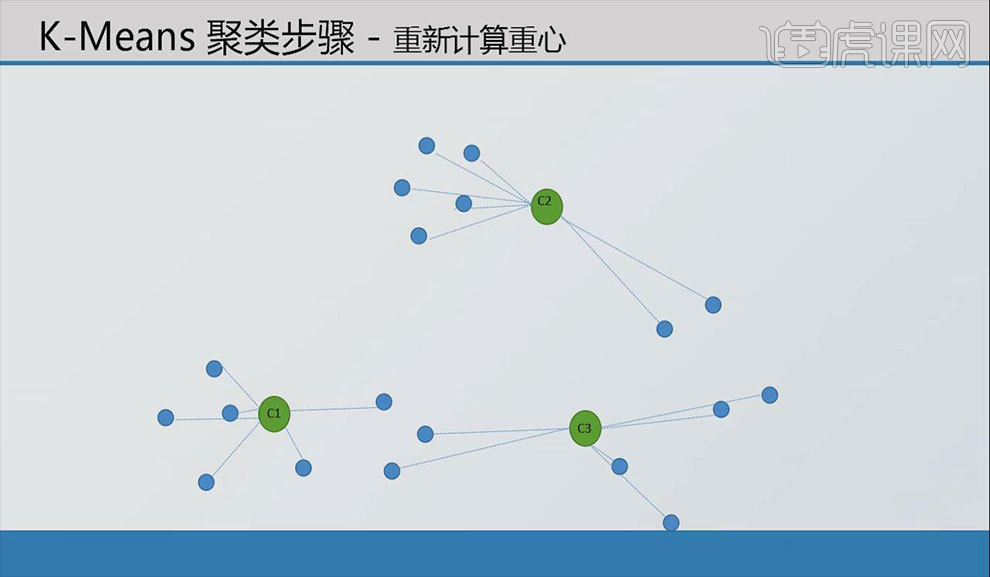
8.重新计算蓝色个体到在中心点的距离,选取距离最近的中心点并把个体分类至该群组中。

9.分组完成后用【计算均值】方法分别计算三个组的中心,得到新的中心点。再次重复迭代之前步骤后会发现中心点的位置不会发生明显的变化即【K-Means类聚】完成。得到如图所示的最佳分群结果。

点击观看视频教程
k均值算法-数据挖掘之客户分群实战
立即学习初级练习4413人已学视频时长:14:47
特别声明:以上文章内容仅代表作者本人观点,不代表虎课网观点或立场。如有关于作品内容、版权或其它问题请与虎课网联系。
相关教程





500+精品图书
20G学习素材
10000+实用笔刷
持续更新设计模板






站内热门

- 扫码下载APP

- 官方微信

为了防范电信网络诈骗,如网民接到962110电话,请立即接听客服热线:400-862-9191
