
商业实战之建模操作演示3发布时间:暂无
1.本节课所讲内容如图所示。

2.Excel表中【dv_response】列为被挑选出可能会参与模型中表示【个体特征的变量】与【目标变量】之间的相关关系。【dv_response】列后的为【待定变量】之间是否有较明显的贡献性。
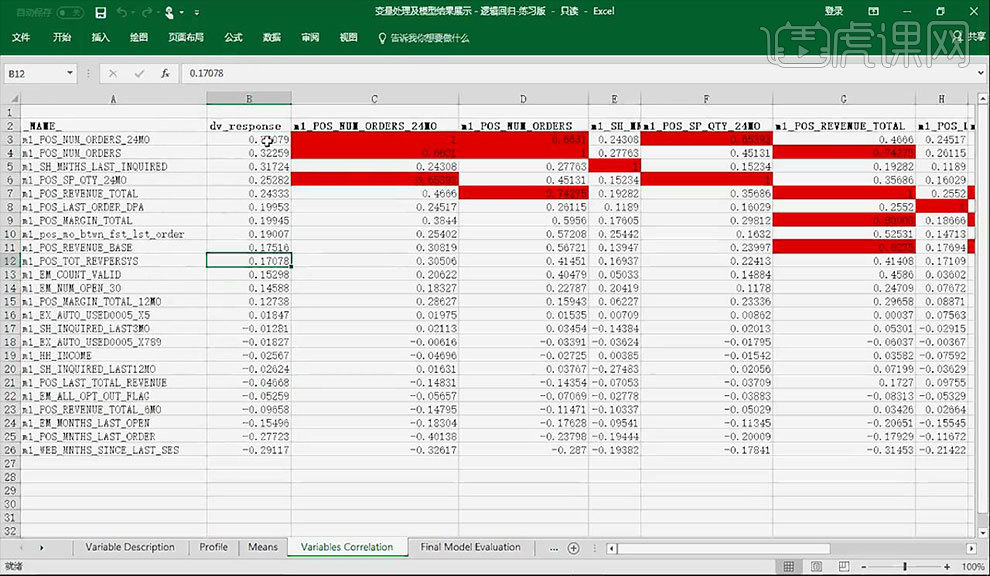
3.对角线上为相同变量1,除1外【红色】部分为几组变量之间可能会有较明显的贡献性。

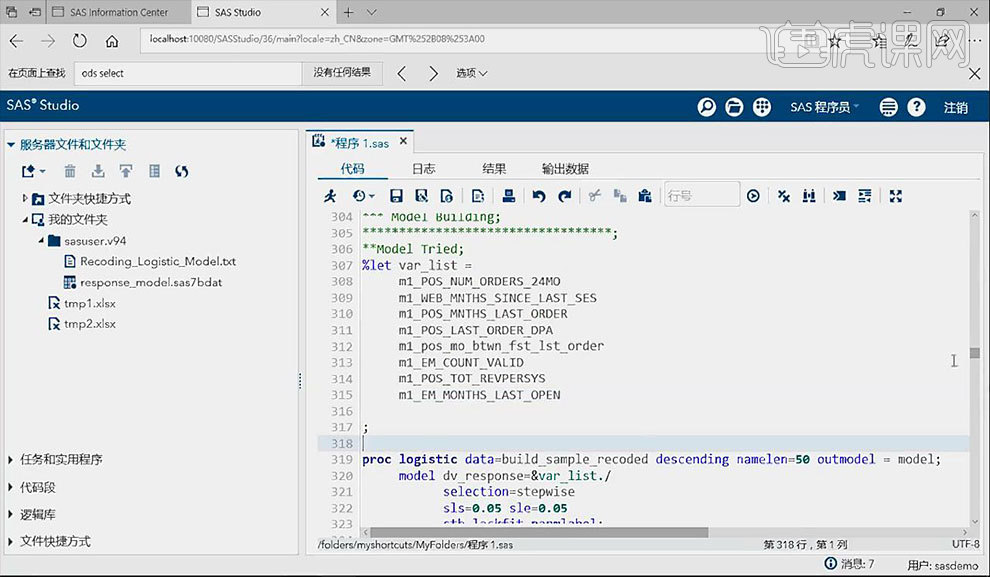
4.建模中主要采用的为【proc logistic】语句。首先将刚才步骤筛选出的变量做成红变量【var_list】,将其放到一起。
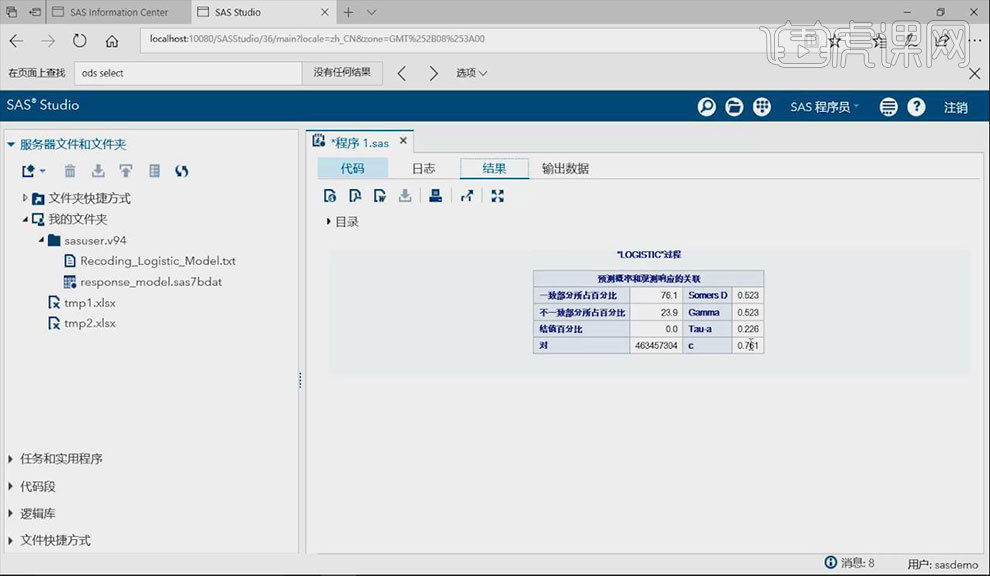
5.选取部分变量来运行【proc logistic】语句,将变量的【剔除概率】和【选入概率】均调制至【0.05】的水平,点击【代码】下工具栏中第一个按钮,运行程序。得出本次调试【c】值为【0.761】,【一致部分所占百分比】为【76.1】。
6.选中查看所需变量vif情况的语句,点击【运行】按钮。根据前方所述标准,【方差膨胀】系数在【2】以下。若vif大于【2】则考虑去除一个变量或者对其中一个变量进行变形或替换等方式。
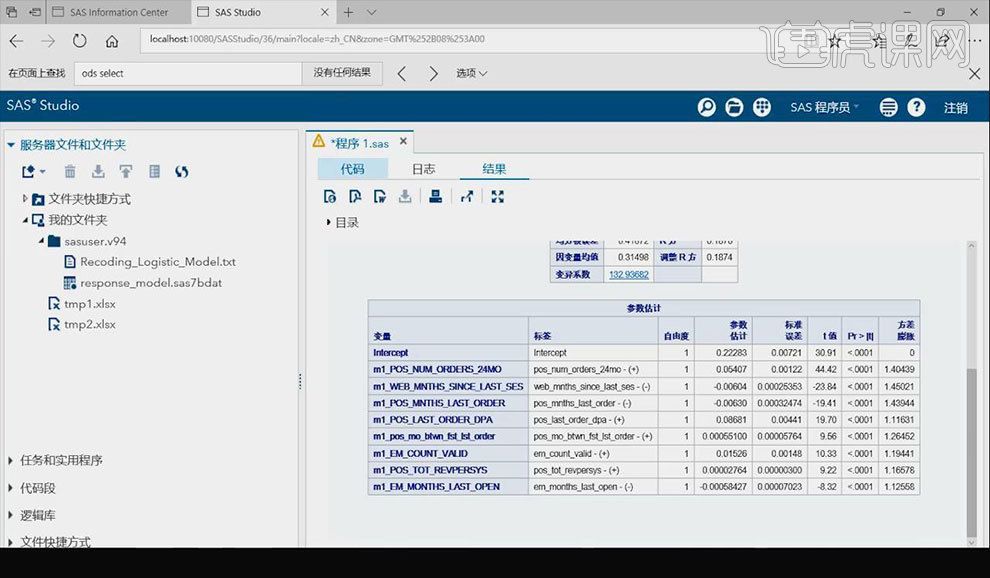
7.选中查看【之前运行逻辑回归过程中输出参数估计结果】的语句,点击【运行】按钮。通过【ProbChiSq】列可知结果都是显著的。【Final Model】列为选出的表示个体特征的变量与【Estimate】列中的数据呈相关关系。

8.首先看的是【Estimate】列的正负相关是否是可解释的。第四行的变量为已做过重编码的变量,其原始变量为表示【过去24个月中的订单数】。将其重编码实则为将其异常值的上下限进行确定,将缺失值进行填补。其相关性是可以解释的。
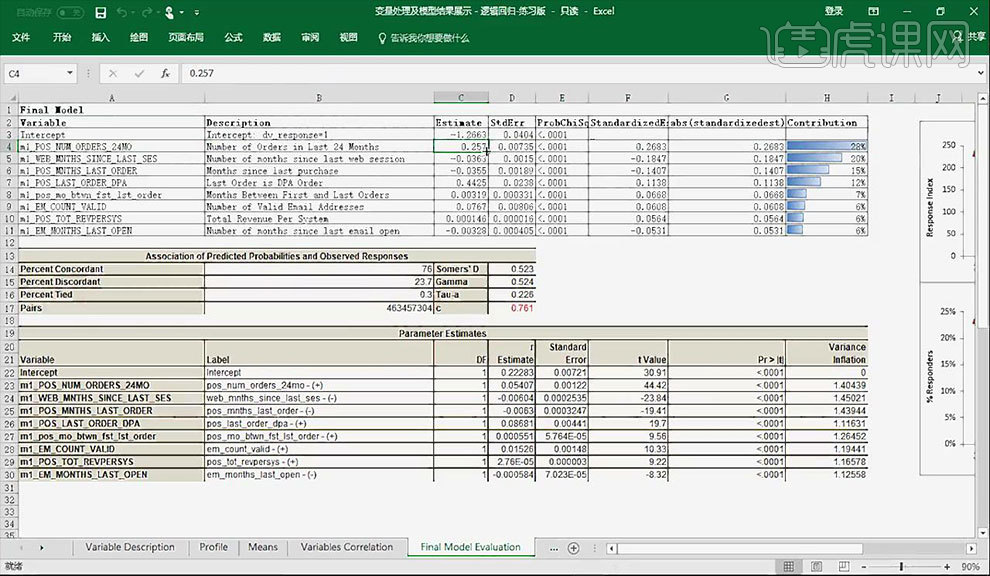
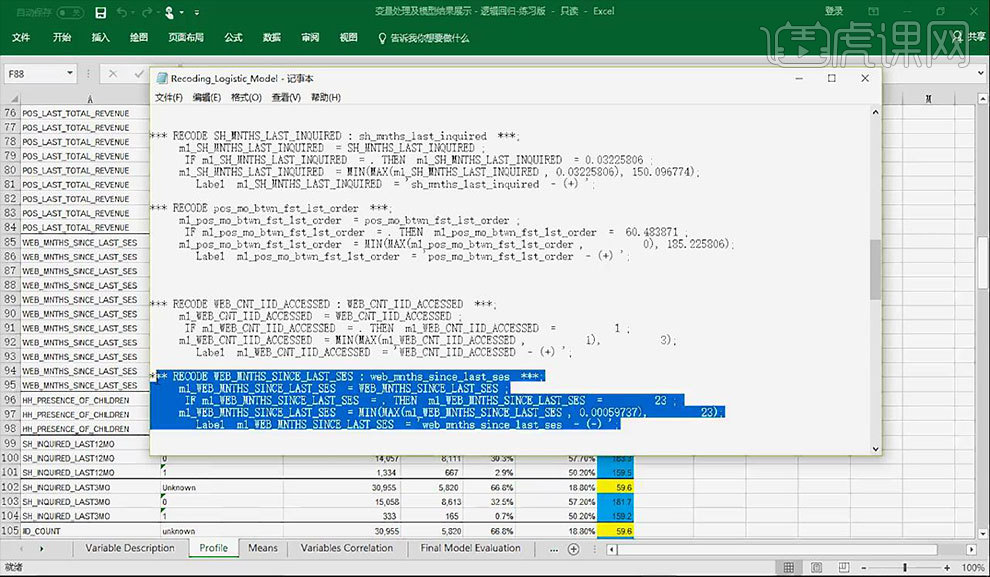
9.第四行的变量其原始变量为【自上次浏览网站后过去的时间】,将其重编码为将其异常值的上下限进行确定,将缺失值进行填补。其相关性是可以解释的。
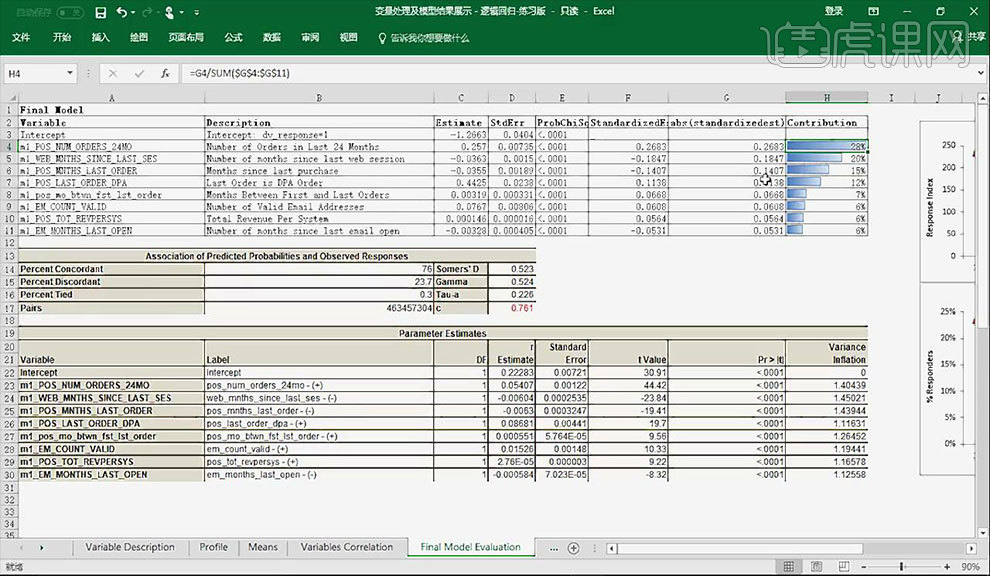
10.【贡献度】的计算方法为将【第一项的标准差】除【所有标准差的和】。为保持模型稳定性,其前几个变量的贡献值应在【30%】以下并不出现一家独大的情况。
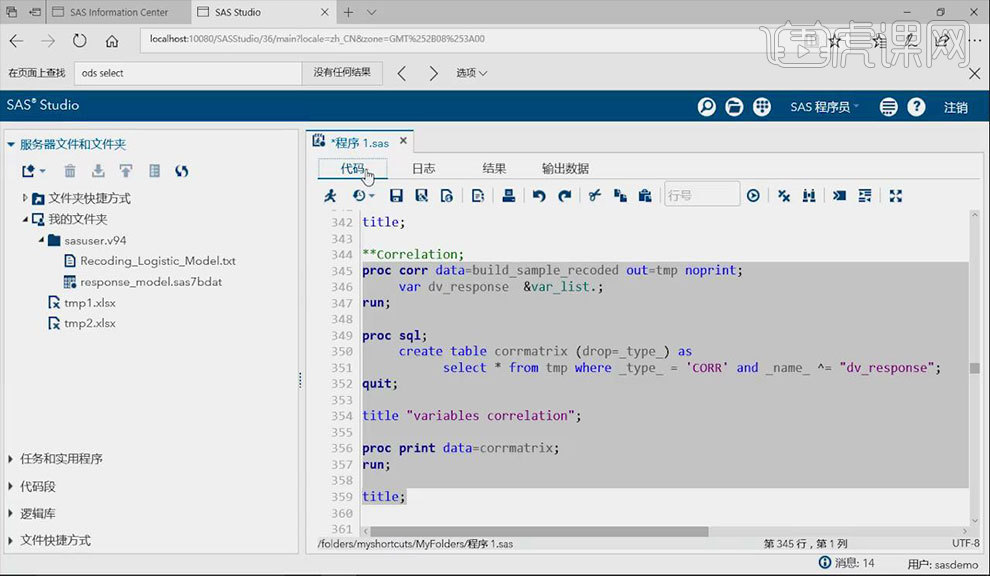
11.选中【对前边vif部分可视化补充】部分的语句,点击【运行】按钮。用于确定两个变量之间没有过大的贡献性。
12.反复调试模型的过程为:【重复建模流程】、【更换变量清单】及【尽量去除相互有较强贡献性的变量】。
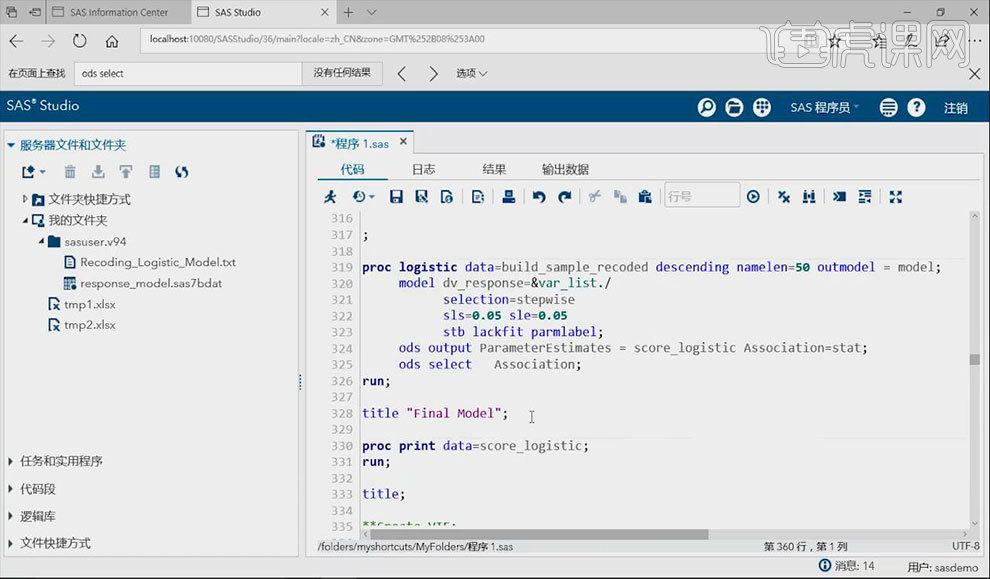
13.选中【所要验证数据集】的语句,点击【运行】按钮。选中【对p_d进行排序,为p_d分配rank】的语句,点击【运行】按钮。
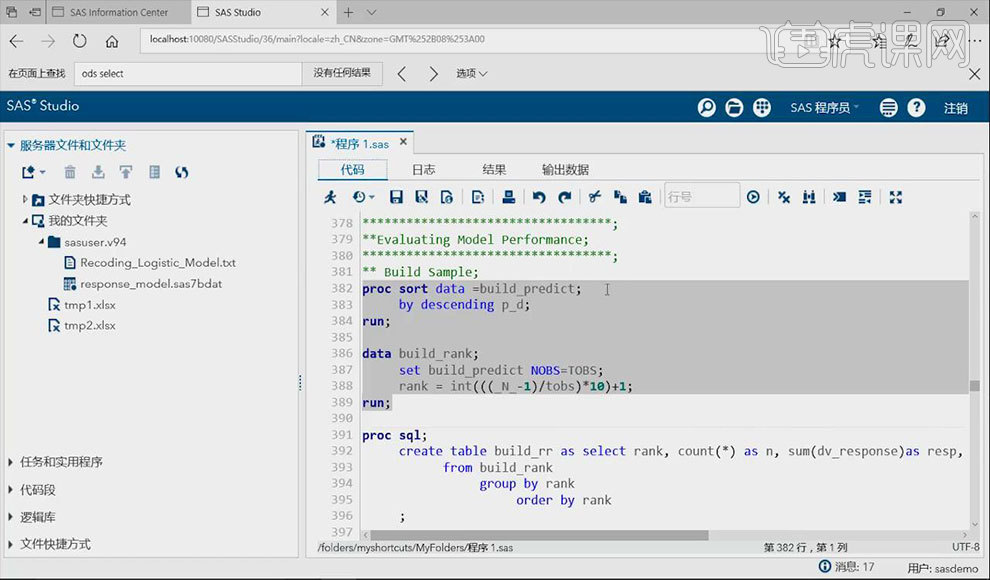
14.选中【计算每个rank的响应率】的语句,点击【运行】按钮。
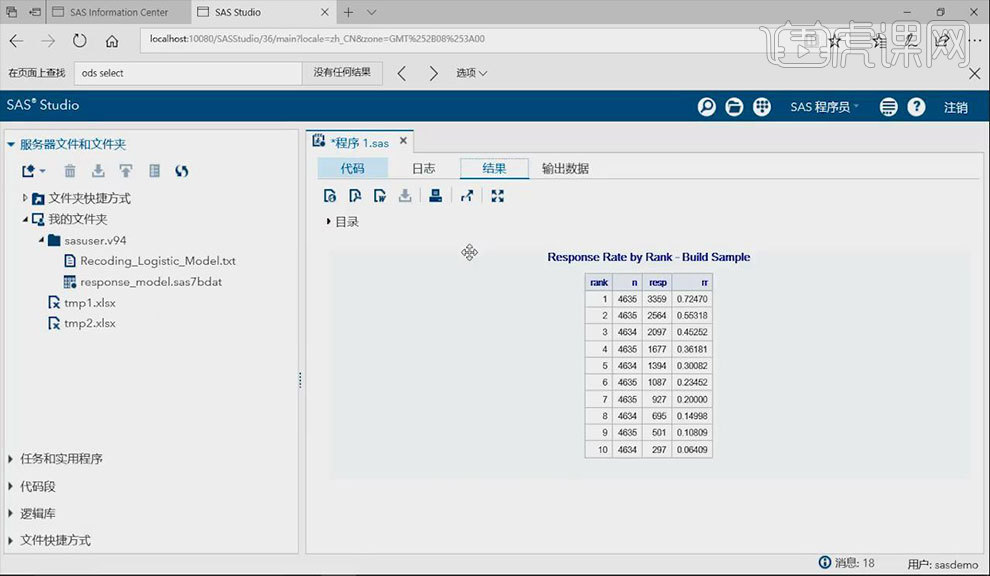
15.上方曲线表示的是【响应率】随着模型得分等级的变化。下方曲线纵轴代表的为【响应的百分比】,其计算方式为:每一个模型的分组上,响应人数占总体响应人数的百分比。
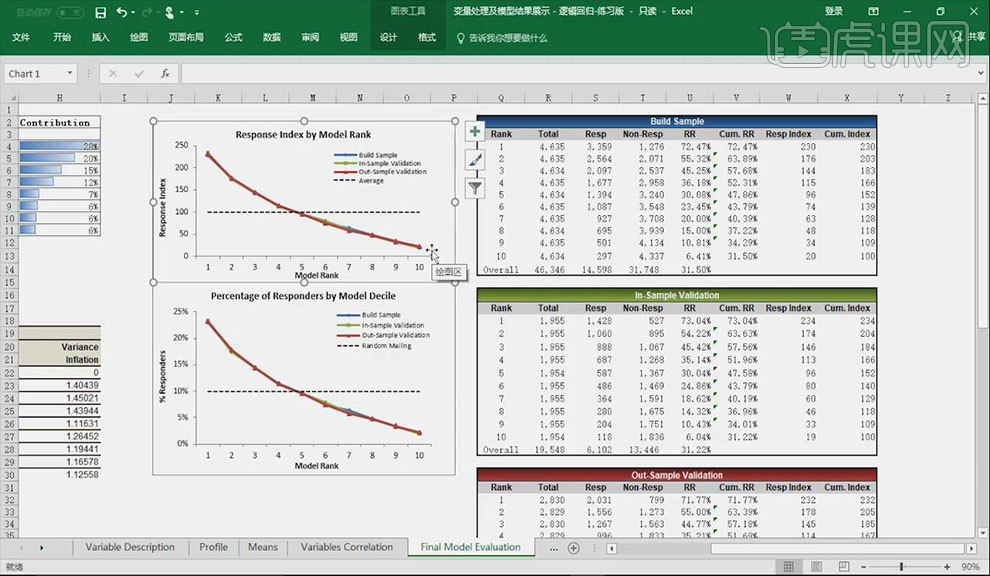
16.选中【输出模型】所需要的代码,点击【运行】按钮。将得分输出到指定的路径中。
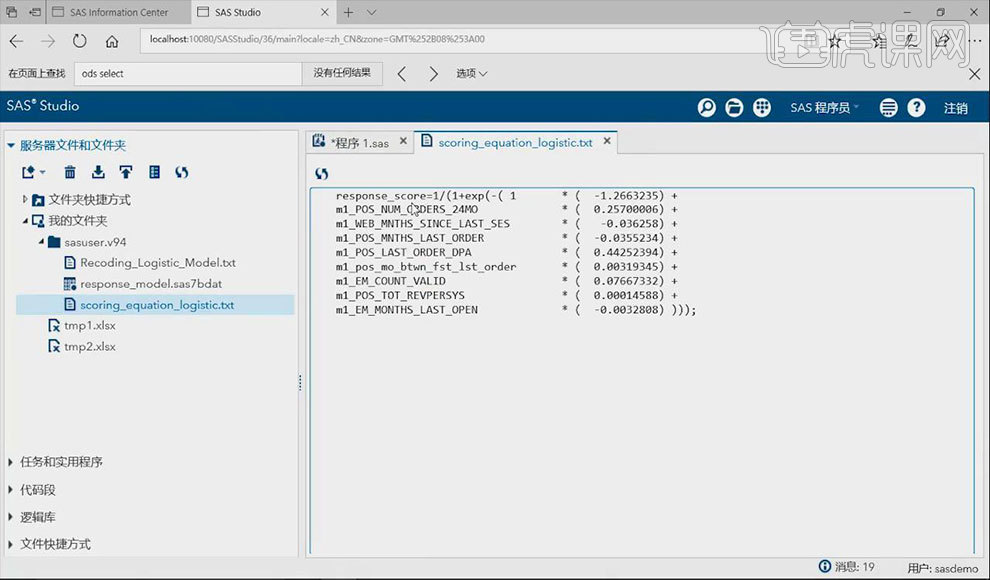
17.通过输出的模型可得出【响应度】从而确定其所处rank值的位置。









站内热门

- 扫码下载APP

- 官方微信

