
博客搜索引擎开发(1)-Python博客系统实战图文教程发布时间:2022年02月21日 08:01
虎课网为您提供字体设计版块下的博客搜索引擎开发(1)-Python博客系统实战图文教程,本篇教程使用软件为Python(3)、Django(3.2.6)、Mysql(5.7)、BootStrap(3.4.1)、 jQuery(2.1.3),难度等级为中级拔高,下面开始学习这节课的内容吧!
那就开始今天的教程吧
1.本节课学习集成搜索引擎,对博客文章的标题、内容进行搜索结果的展示,比如说可以在网站中搜索任意想要的一个关键字,找到与这个关键字有关联的所有博客文章,这个也是内容网站必须要有的核心功能,
学习在Django这个框架下,在Python领域中搜索引擎方面有哪些核心的三方库,以及Django是如何集成这些三方库在Web项目中实现搜索的功能,这一讲就是为博客系统添加搜索引擎,能够展示这种按关键字检索的文章内容。
在Python领域中与搜索相关的三个主要的三方库,【haystack】是一个搜索相关的支持的三方库,核心底层会用到whoosh,【whoosh】是比较著名的一个搜索引擎,【jieba】支持中文的分词库,它们三个互相结合在一起,
再被Django框架集成进来,就可以用配置的这种方式来在Django这种框架中开发搜索引擎功能。

2.【whoosh】在所有要检索的内容发生变化的时候,它会有索引文件生成出来,下一次的查找都是在索引里边去查找,不是每次都通过这种持久化的数据源,从文件中再去读取原始的文章内容,这个是搜索引擎它的核心价值,
【haystack】与Django是中间的衔接框架,它开发了很多的API和路由的功能,它的核心会调用whoosh来完成索引和引擎文件的配置和生成的过程,然后whoosh在生成搜索文件的时候,它就会结合着jieba分词库对中文有比较好的支持,
但是haystack核心不仅限于使用whoosh这个库,它还有其他的一些库也是支持的,然后分词引擎也不仅仅只有jieba一个,但是在Django的这个框架中比较推荐。

3.回到开发工具Pycharm中,不是装原生的haystack三方库,要装经过Django和haystack结合二次开发的封装包,叫【django_haystack】,之后再装pip install,是whoosh,然后装pip install jieba,然后来进行配置,
因为Django是国外开源的项目,它底层默认配置的分词器不是jieba,要把它进行替换,在haystack找到whoosh_backend,这个要根据你的环境来配置,在你用的Python解释器的三方库环境下找到haystack这个包,
它下面有一个子目录叫backends,下面有一个脚本叫whoosh_backend,不建议直接改它。

4.比方说放到blog应用下,因为当前的这个搜索引擎就是为blog这个应用来配置的,给它改名字叫cn,要引入jieba提供的分词类,【from jieba.analyse】 就是分析import一个类,这个类是ChineseAnalyzer中文的分析器,
把它导入到whoosh的配置脚本中,找第244行,也就是用到分词器的位置,它现在用的是StemmingAnalyzer,这行注释掉,换成jieba提供的中文的分析器。

5.ReadMe第一讲的时候写过了搭建项目框架的过程,haystack搜索引擎的配置与开发,第一步要安装三个包,三方库都包括【django_haystack,jieba,whoosh】,把它们三个安装好,第二步是重新配置jieba的分词器,
要找到自己环境中haystack三方库的位置,把里边haystack这个目录给大家写一下,然后把backends下面的whoosh_backend.py拷贝出来放到blog目录下,并且改成你自己的名字,加下划线cn,还是加什么都可以。

6.然后修改文件内容,内容有两处,第一步【引入jieba分词类】,第二步【替换原有的分词类】,大概在244行左右,这个大家一定要自己找,因为很有可能会变,因为haystack跟blog一样,它就是一个APP应用,
安装完了之后像CKEditor,要在settings中把它加入到应用中,除了blog comments就是自定义的应用之外,像CKEditor这两个也是需要加进来的,同样haystack也是一个应用包,它和我们自己创建的没什么区别,要把它引入进来。

7.加完之后要对haystack进行配置的工作,要让haystack和Django进行集成,需要让Django知道haystack在哪里,它的引擎是什么,最后要加上haystack的配置,首先haystack要有它的CONNECTIONS,
就是连接haystack搜索的一些相关的配置,引擎在哪里,搜索文件的目录在哪里也是需要给出来的,【default】有字典类型的参数,第一个就是配置引擎,引擎叫ENGINE,放在whoosh_backend_cn.py,引擎里边它有一个类,
这个类叫WhooshEngine,就是用到的whoosh的引擎类,它就用这句话将引擎和haystack这个框架进行了集成。

8.引擎中间会有一些索引的文件,索引文件位置叫PATH,要先获取到项目的根目录,用os.path.join拿到BASE_DIR,那就是项目的一个根目录,再制定索引文件的目录名字叫whoosh_index,如果你没有非常大的这种个性化的需求的时候,
像这种配置不要去改动它。

9.搜索引擎还会有一些应用层面的配置,比方说页面和索引机制的配置,第一个叫HAYSTACK_SEARCH_RESULTS_PER_PAGE,就是搜索结果的PER_PAGE,就是每一页要展示几个,因为它是一个被封装的应用类,这里用到分页的概念,
然后定时的更新,就是在文章内容进行改变的时候定时更新索引文档,索引的结果肯定是要更新的加上【HAYSTACK_SIGNAL_PROCESSOR】,这个叫过程的信号执行器,haystack.signals.RealtimesSignalProcessor,
就是实时的标记处理器SignalProcessor。

10.settings中增加两个配置,第一个是【APPS增加haystack】,第二个是增加【haystack的相关配置】,接下来要配置在搜索过程中用到的脚本文件,这个搜索引擎搜索的是博客的文章,也就是说搜索引擎是配置给blog这个应用的,
跟comments没有关系,要在blog下面创建搜索引擎要调用的脚本文件,这些都是约定的,所以它的命名都是固定的,这个文件叫search_indexes.py,一个复数形式的indexes脚本,这个名字一定不要写错。

11.搜索的索引获取文件,它里边是要定义搜索引擎所要查找的内容范围或者是获取的方法,这里要强调这个文件名字是固定的,因为它是Django集成了haystack之后默认的名字,不要去改它,然后引入from haystack import的包,
这个包叫indexes,就是索引,然后这个类定义的名字也是固定的class,别管是标题还是文章的内容都是在Bloginfo这个模型下,后面加一个index作为类名,这是固定的,没有任何的可以修改的可能,你要搜索哪个模型,
你就把模型写在前面。

12.搜索目标的模型类名加上【Index】作为搜索索引类的名字,这个类比较特殊,必须有一个父类才能知道它是用来做什么的,刚才引入了indexes,要继承两个父类,一个是搜索索引【SearchIndex】,一个是【indexes.Indexable】,
就是它是一个可被索引的Indexable,继承这两个父类。

13.首先设定一个搜索结果字段,这个字段就是要定义的变量名,比方说搜索结果就叫text的文本,然后它是indexes.CharField,也是一个文本类型的字段,然后是document两个参数要给出来,document等于True,use_template等于True,
这个是固定的配置,其实像haystack whoosh等等这些三方库也是可以独立运行的,可以自己去集成到你的框架中,搜索的结果就是放到一个text的文本中。

14.要重写两个方法,第一个叫【get_model】,这个model返回一个模型,也就是要用model来处理后面对数据库的操作,这个直接就返回Bloginfo,要给它引入进来返回模型的类, from.models import Bloginfo,
就是传递一个类的定义,而不是一个对象,不用实例化,模型从model里定义的Bloginfo类实际上就是数据库表的结构,每一个Bloginfo类的对象当于是数据库表中的一条记录,要搜索的是检索的和创建引擎范围中用到的是哪个数据库表,
这里直接把类返回回去就可以了,不需要说把它实例化。
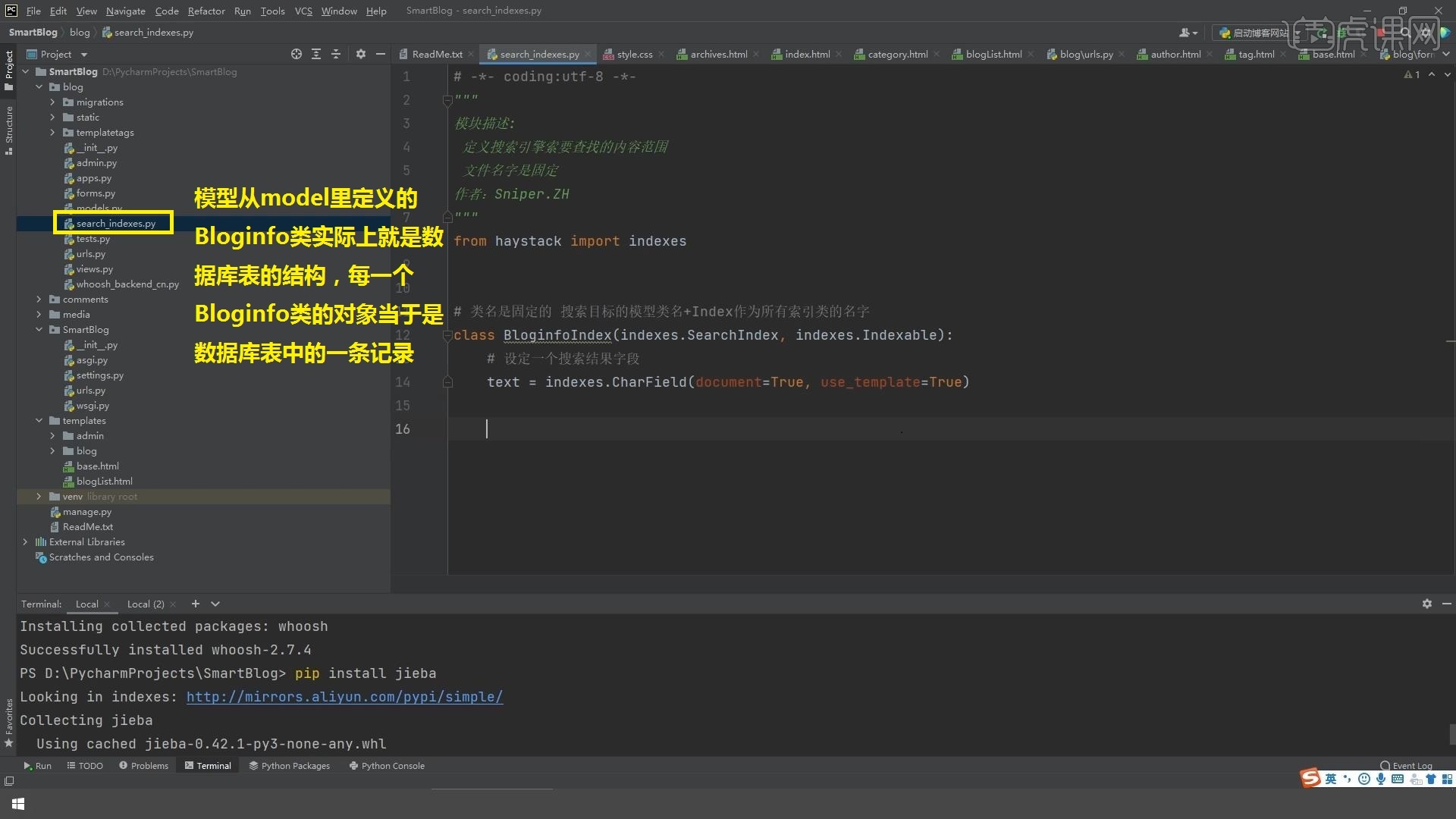
15.现在默认搜索的就是所有的文章self.get_model,就是拿到了Bloginfo,不要直接写Bloginfo,因为它是一个联动的关系,.objects.all,就是把所有的文章拿回来,然后在这个范围内进行检索,现在就是在所有的文章中要建立索引,
第一个配置指定了搜索的模型和搜索的范围,下一步配置在搜索中要对哪些字段进行搜索,这也是一个约定,在模板层下面建立search目录,这个必须是固定的,因为这些配置是被封装到haystack的这个应用中,再创建一层子目录,
这层子目录叫索引indexes,search indexes下面要搜索的是Blog应用。

16.再来一层目录,下面要创建txt文件,创建一个File,这个文件中要加两个内容,里边写object.title,【object】 代表的是模型的对象,模型是bloginfo,要对标题和文章的内容主体这两部分都进行索引的创建,还是写到ReadMe里边,
要创建两个脚本配置文件,第一个是search_indexes.py,这个文件定义了索引创建依赖的model和搜索目标的范围,就是你是要在全部的文章中来查找还是在其中的某一部分来查找。
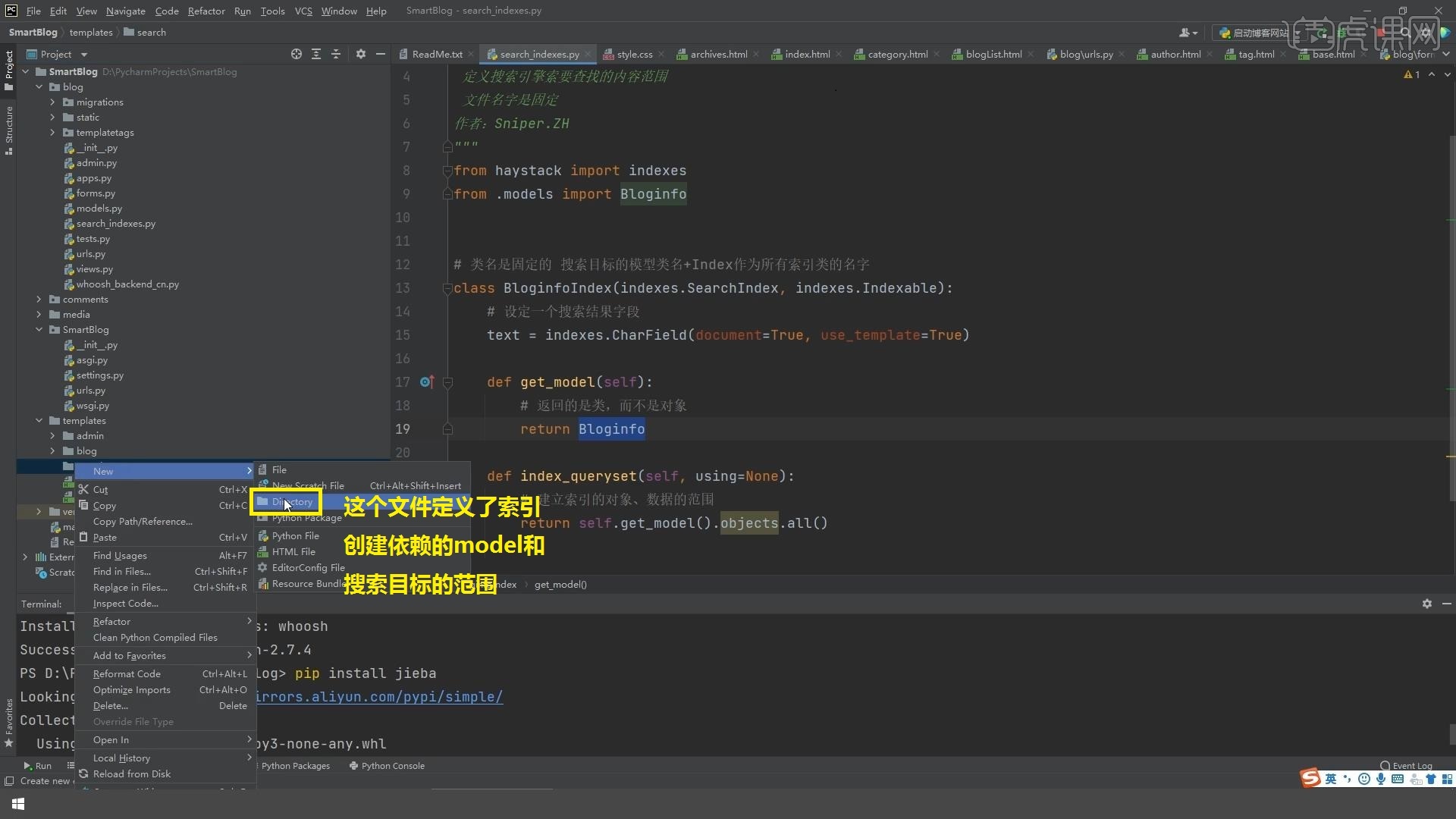
17.还定义了templates下面的search下面的indexes下面的blog,这个目录的层级都是有意义的,【search】表示这是搜索引擎要用到的一些模板,然后【index】是创建索引的时候用到的,创建的是blog这个APP的索引,
下面这个文件名是bloginfo这个模型的索引,索引的名字是text,以上命名大多数都是约定好的,不能随意修改,就是必须按照这个规则来定义。

18.下面来配置haystack所要用到的一些网络请求的路由,haystack它作为一个应用被集成到Django项目中,像CKEditor都是一样的,也是用include就可以,用search这个路径,包含了include进来haystack定义到的URL,
因为它下面也有URL的一些配置,然后建立前台搜索结果的模板,就是搜索完了之后结果应该在哪里去展示,这个页面也是要按照约定来创建,这个文件应该创建在【search】这个目录下,它的名字就叫search.html,
都是为了索引创建搜索结果而用的,不要起其他的名字。

19.第5步创建搜索结果展示模板,展示模板必须放在templates search search.html,必须这样命名,因为它是haystack这个包源码中规定好的,extends继承base.html,也要继承自这个模板,if有没有判断对象叫query if query,
只有query被实例化之后才是一个检索结果的页面,加else先把整体的结构给出来,没输关键词进入到这个页面没有什么意义。

以上就是博客搜索引擎开发(1)-Python博客系统实战图文教程的全部内容了,你也可以点击下方的视频教程链接查看本节课的视频教程内容,虎课网每天可以免费学一课,千万不要错过哦!







站内热门

- 扫码下载APP

- 官方微信

