虎课网-专注职业教育
拖动LOGO到书签栏,立即收藏虎课网

python基础教程亚马逊图书信息怎么爬取?发布时间:2021年04月15日 17:05
我们都知道用python可以在网上爬取很多数据,但你知道具体应该怎么操作吗?今天小编给大家带来的教程是“python基础教程亚马逊图书信息爬取”,如果你对用python爬取信息还不是很熟悉,学习完接下来的教程,应该会有很大的进步,一起来看看吧。
1.找到你要获取页面信息的链接,这里以一本图书为例来说明。具体如图所示。

2.复制它的链接。具体如图所示。

3.导入requests库,获取相应链接的返回信息。具体如图所示。

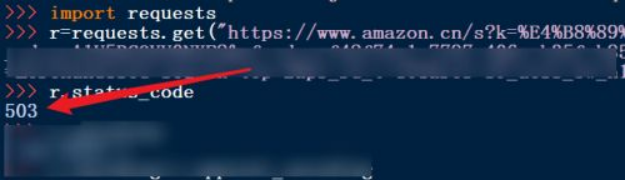
4.输入状态码,返回相应的返回状态。返回的状态如果是200,这说明访问成功。否则,返回失败,这里是503,说明访问失败。具体如图所示。
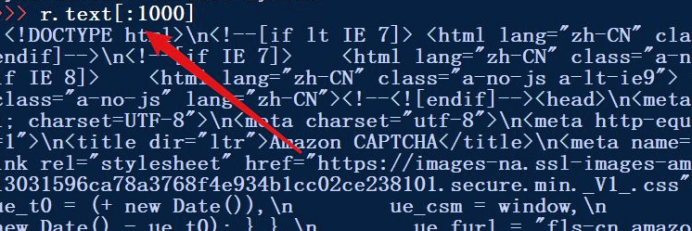
5.根据返回的信息判断可能是由于访问进行限制。接受的是由于浏览器发出的http请求。所以通过网站访问的http的头部判断请求。具体如图所示。

6.服务器判断出访问是由于python的requests库的程序的进行的。因此,修改访问头部的信息,模拟浏览器访问状态。
7.首先构造一个字典类型,修改 user-agent的信息。具体如图所示。

8.重新提交访问请求。具体如图所示。

9.再次检查访问状态。下图说明访问成功。具体如图所示。

10.获取访问的信息就可以了。具体如图所示。
上面就是“python基础教程亚马逊图书信息爬取”的全部内容了。python是目前行业内比较流行的编程语言,其中,requests库是信息爬取很重要的库,通过获取亚马逊图书页面信息的这个例子,我们可以熟悉页面信息爬取的各个技巧,对我们python技术的提升很有帮助哦。
本篇文章使用以下硬件型号:联想小新Air15;系统版本:linux;软件版本:python。
点击观看视频教程
爬取网页内容-python办公自动化之网络实战篇
立即学习初级练习6253人已学视频时长:05:47
特别声明:以上文章内容仅代表作者wanrong本人观点,不代表虎课网观点或立场。如有关于作品内容、版权或其它问题请与虎课网联系。
500+精品图书
20G学习素材
10000+实用笔刷
持续更新设计模板






站内热门

- 扫码下载APP

- 官方微信

为了防范电信网络诈骗,如网民接到962110电话,请立即接听客服热线:400-862-9191
